Exclusive: Meta’s AI Agent Swarm Successfully Maps 4,100-File Pipeline, Slashes Errors by 40%
Breaking: Meta Achieves Full Code Coverage with Autonomous AI Knowledge Mapping
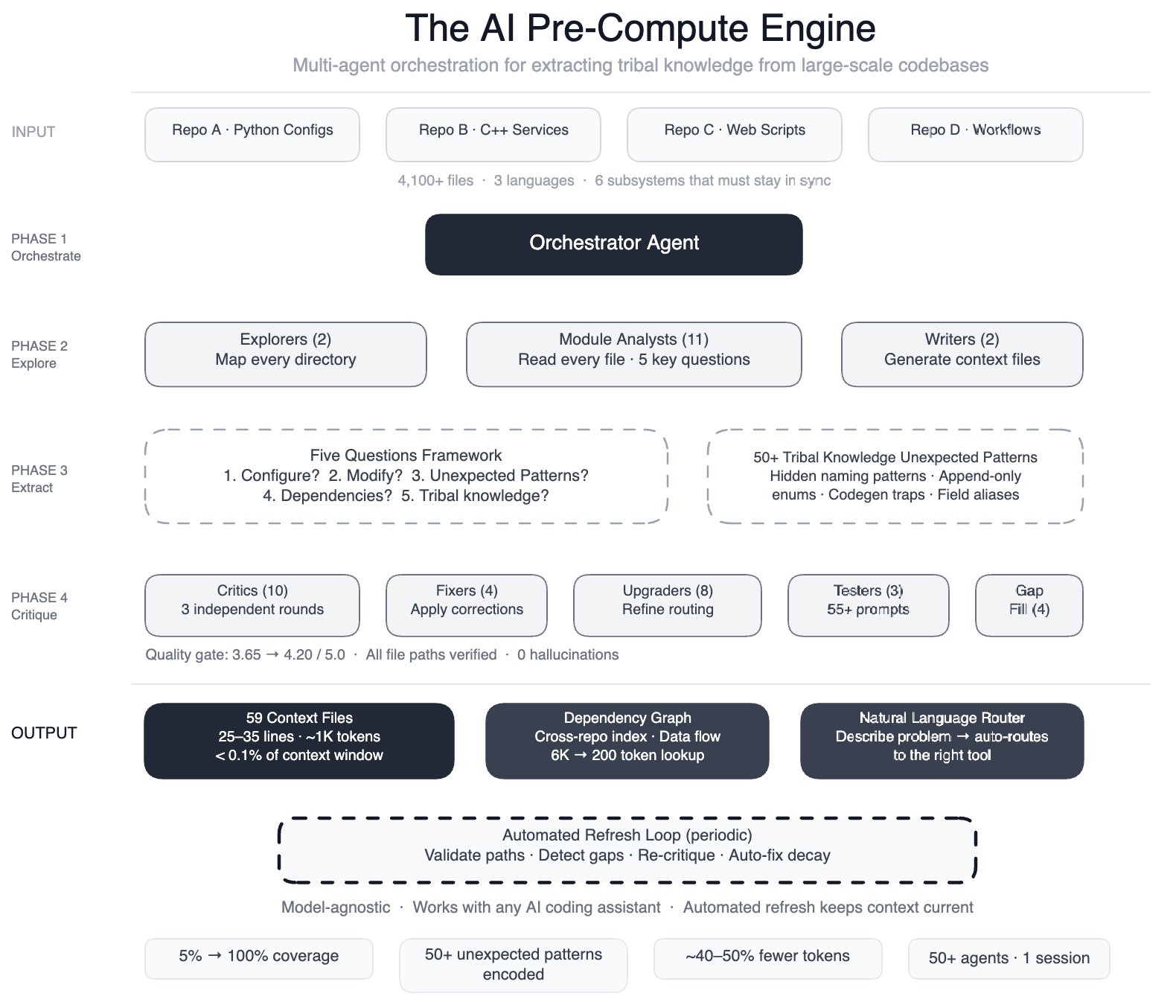
MENLO PARK, CA – March 2025 – Meta has unveiled a breakthrough method to encode human ‘tribal knowledge’ into a machine-readable layer, enabling AI coding assistants to navigate a sprawling data pipeline of over 4,100 files across four repositories and three languages. The system, a pre-compute engine powered by a swarm of 50+ specialized AI agents, has boosted code-module coverage from 5% to 100% and reduced AI tool calls by 40% in preliminary tests.

“Before this, our AI agents were like tourists without a map—they’d wander, guess, and often produce code that compiled but was subtly wrong,” said a Meta engineering lead familiar with the project. “Now they have structured navigation guides for every single module.” The knowledge layer is model-agnostic, meaning it works with leading large language models from OpenAI, Anthropic, and others.
The Problem: AI Tools Without a Map
The pipeline in question is a config-as-code system spanning Python, C++, and Hack, where onboarding a single data field touches six subsystems that must stay in sync: configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts. When Meta tried to extend existing AI-powered operational tools to development tasks, the agents failed because they lacked understanding of non-obvious patterns—such as deprecated enum values that must never be removed due to serialization dependencies.
“Without this context, agents would make dozens of incorrect tool calls, wasting time and risking silent data corruption,” the lead explained. The team needed a way to capture the mental models that veteran engineers carry in their heads and serve them directly to AI.
The Approach: Teach the Agents Before They Explore
Meta built a pre-compute engine using a large-context-window model and task orchestration in discrete phases. Two explorer agents first mapped the entire codebase. Then 11 module analysts read every file and answered five key questions about purpose, inputs, outputs, edge cases, and interdependencies. Two writers generated 59 concise context files documenting 50+ non-obvious patterns, such as configuration field name swaps that could silently produce wrong output.
Quality was ensured by 10+ critic passes running three rounds of independent review, followed by four fixers applying corrections, eight upgraders refining the routing layer, three prompt testers validating 55+ queries across five engineering personas, four gap-fillers covering remaining directories, and three final critics running integration tests. “We orchestrated over 50 specialized tasks in a single session—essentially a factory of AI agents working in assembly-line fashion,” the lead said.
Results: 100% Coverage, 40% Fewer Tool Calls
The outcome: AI agents now have structured navigation for 100% of code modules (up from 5%), covering all 4,100+ files across three repositories. Preliminary tests show a 40% reduction in the number of AI agent tool calls per task, meaning agents reach correct edits faster without exploratory guesswork. The system also self-maintains—automated jobs periodically validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references.
“The AI isn’t just a consumer of this infrastructure; it’s the engine that runs it,” the lead emphasized. The knowledge layer is model-agnostic, ensuring compatibility with future LLMs without re-engineering.
Background: The Challenge of Tribal Knowledge in Large Codebases
Tribal knowledge—the unwritten rules, design decisions, and historical context held by experienced engineers—has long been a bottleneck for AI-assisted coding. Traditional approaches rely on documentation that quickly grows stale or on fine-tuning models with snippets, which misses cross-file relationships. Meta’s pipeline, with its multiple languages and repositories, amplified this challenge. The team initially tried using AI to scan dashboards and match patterns for operational tasks, but development tasks required a deeper map of intent.
“We realized the AI needed to understand why things were done a certain way, not just what the code does,” the lead said. This drove the creation of the pre-compute engine, which treats knowledge extraction as a parallelizable, systematic process.
What This Means for AI-Assisted Development
Meta’s approach offers a blueprint for enterprises grappling with legacy codebases and AI adoption. By encoding tribal knowledge into a structured, self-updating layer, companies can dramatically improve the reliability of AI agents without retraining models. The 40% reduction in tool calls translates to faster development cycles and fewer costly errors, especially in complex, multi-repo environments.
“This is a step toward AI that truly understands the software it’s helping to build,” the lead concluded. “It’s not just about writing code—it’s about preserving and leveraging the collective wisdom of engineering teams.” Meta plans to open-source elements of the approach, though no timeline has been announced.